띵동, 배달 음식도 추천이 되나요?

집에 있는 몇 장의 전단지를 보고 배달 음식을 주문했던 과거와 다르게, 이제는 모바일 앱만 열면 수많은 음식점의 전단지를 한 곳에서 볼 수 있습니다. 선택의 폭이 넓어졌다는 장점이 있지만, 음식점 리스트를 확인하고 주문을 하기까지 그만큼 많은 시간을 소비하게 됩니다. 일반적으로 배달 음식 앱에는 음식 카테고리마다(한식, 중식 등) 음식점이 분류되어 있긴 하지만, 여전히 음식점 리스트는 줄어들지 않습니다. 음식 카테고리를 세분화하는 것에도 한계가 있기 때문입니다. 이렇게 음식 카테고리를 이리저리 들어가 보고, 음식점 후기도 꼼꼼히 읽으면서 어떤 음식을 주문할지, 어떤 음식점에 주문해야 할지 고민하면서 시간을 소비할 수밖에 없습니다. 음식 추천 시스템은 우리가 원하는 혹은 좋아할 것 같은 음식점을 추천해 줌으로써 선택지를 좁혀주고, 더 나아가 먹고 싶은 음식을 먼저 제안해주는 방법으로 우리의 시간과 노력을 줄여줍니다.
추천 시스템(Recommender System),
그리고 개인화 추천(Personalized Recommendations)
추천 시스템(Recommender System)은 3차 산업혁명의 산물인 데이터가 만들어 낸 대표적인 시스템입니다. 과거에 off-line으로 한정되었던 선택지가 on-line으로 옮겨오면서, 우리에게 주어진 선택지는 기하급수적으로 늘었습니다. 접근할 수 있는 정보의 양이 증가함과 동시에 우리가 원하는 것을 찾아서 선택하기까지의 과정이 이전보다 어려워졌고, 이 상황을 정리해 줄 누군가, 혹은 어떤 것이 필요했습니다. 여기서 추천 시스템이 등장하고 현재 우리는 생활 속에서 다양한 모습으로 추천 시스템의 도움을 받고 있습니다.
추천이라는 주제에서 가장 먼저 언급되는 keywords는 Amazon과 Netflix인데요. 이들이 지금까지 만들어 온 “추천”이라는 contents는 단순히 선택을 도와준다는 정의를 넘어서 개인화 추천(Personalized Recommendations)의 영역으로 접어들었습니다. 한 사람의 Neflix 계정 메인 페이지는 오로지 한 사람을 위해 정의된 페이지라는, 즉 영화 목록에서 각 영화의 preview 화면 이미지(영화 스틸컷)까지도 내가 좋아할 것들만 모아놓은 나만을 위한 공간이라는 뜻입니다.
Everything is a recommendation! Over 80% of what people watch comes from our recommendations. — Netflix
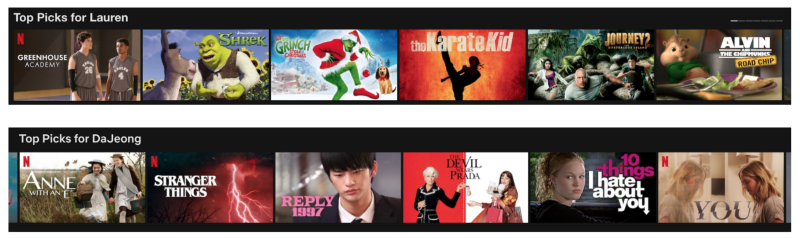
개인화 추천도 더 이상 새로운 것이 아니며, 많은 서비스에서 다양한 모습으로 사용되고 있습니다. 가깝게는 음악 추천 혹은 쇼핑 상품 추천 등 다양한 분야에서 개인화를 추구해가고, 더 정확하고 효율적인 개인화를 위한 연구/개발도 빠르게 성장해 가고 있습니다. 띵동에서는 띵동의 서비스들, 즉 음식배달과 생활편의 서비스 또한 개인화와 추천이 가능한 영역이 될 수 있다는 생각을 가지고 추천 시스템을 도입하였습니다. 본 글에서는 대중적인 추천 시스템에 대한 자세한 이야기보다는, 띵동이 가진 추천 시스템의 모습을 공유하려고 합니다.
띵동의 음식점 추천 시스템(Restaurant Recommender System) 도입,
단순한 음식 카테고리 추천이 아니다.
띵동의 서비스는 음식 배달 뿐만 아니라 고객들의 생활 속 다양한 니즈(needs)를 위해 운영되고 있으며, 그만큼 다른 분야 못지 않게 다양한 컨텐츠(contents)들을 모바일 앱에 담고 있습니다. 그렇기 때문에 더욱 ‘추천’과 ‘개인화’에 적합한 서비스라고 생각했습니다. 고객들이 앱 서핑(App surfing)에 시간을 할애하지 않고도 개인이 원하는 음식, 서비스를 먼저 제안받는 서비스, 더 나아가 띵동 앱이 단순한 딜리버리 서비스를 이용하기 위한 앱이 아닌, 개인의 취향을 담고 있는 온디맨드 딜리버리 서비스 앱이 되어야 한다고 생각합니다.
추천 시스템 구축에 앞서, 현재 띵동 서비스의 특성들에 대한 파악이 선행되어야 했습니다. 처음부터 전체 서비스를 대상으로 접근하기 보다는, 음식점 추천에서 시작하기로 했습니다. 일반적인 추천 시스템이 당면하는 문제점(i.e.,sparsity, cold start)과 더불어, 음식점 추천이기 때문에 고려해야할 부분들이 있습니다.
- 시간적, 공간적 제약
24시간 추천이 가능한 음악, 영화 혹은 상품과 달리, 음식점 추천에는 시간적, 공간적 제약이 있습니다. 음식점 영업 시간이라는 시간적 제약과 배달이 가능한 지역인지에 대한 공간적인 제약이 수반되는 점을 고려해야 하기 때문에, 언제나 이용가능한 추천 리스트를 만들기가 어렵습니다. - 상대적으로 큰 기회비용(opportunity cost)과 한정된 주문/구매 사이클(cycle)
영화와 음악 추천과는 다르게 음식 주문에는 보고, 듣고 테스트 해볼 수 있는 trial에 대한 개념이 없습니다. 따라서 음식 주문을 할 경우, 음식에 지불하는 비용과 식사 한끼에 대한 기회비용이 존재하게 됩니다. 즉, 다른 영역보다 음식 주문에 있어서는 새로운 것(i.e., 안 먹어본 음식을 주문하는 것)에 쉽게 접근하기 어려운 점이 있습니다. - 하루에 마주하는 3끼의 식사, 추천 시점과 패턴 파악에 대한 중요성
하루 평균 3끼의 식사를 한다고 가정했을 때, “끼니” 라는 개념은 음식을 주문하는 가장 기본적인 패턴이자 음식점 추천이 나누어져야하는 기준이 될 수 있습니다. (물론, 커피, 베이커리, 혹은 간식류는 해당되지 않을 수 있습니다.) 하루 3끼를 모두 동일한 음식을 주문하는 경우는 매우 적으며, 끼니 마다 선호하는 음식의 종류가 다릅니다. 점심에 선호하는 음식의 종류과 야식으로 선호하는 음식의 종류는 같이 않을 확률이 높습니다. 따라서 적절한 시점(time of day)과 음식이 주문되는 패턴을 분석하는 단계가 필요합니다.
Sparsity & Cold Start Problem (희소성 & 콜드 스타트)
추천 시스템이 가진 대표적인 문제인, Sparsity와 Cold start problem은 같은 맥락으로 생각해 볼 수 있습니다. 두가지 문제 모두 “고객이 주문한 음식보다는 주문하지 않은 음식점이 더 많으며, 모든 주문에 별점를 주지 않는다”에서 시작됩니다. 일반적으로도 고객(사용자)들은 전체 제공되는 products의 평균 4% 정도만을 사용/평가 한다고 알려져 있습니다. 즉, 알고리즘적인 관점으로 보았을 때, User(고객), Item(음식점)과 Rating(음식점 평가) 3가지 요소로 구성된 matrix에서 비어있는 값(cells)이 대부분이라는 이야기가 됩니다. 이러한 sparsity problem은 추천의 정확도가 낮아지거나 추천이 어려워지는 상황을 발생시키게 됩니다.
초기 정보 부족의 문제, 즉 새로운 고객과 음식에 대한 경우가 바로 Cold start가 됩니다. 일부 추천 알고리즘의 경우, 과거에 쌓인 정보를 기반으로 추천을 하는 방식이며, 이 때 신규 음식점의 경우나 신규 고객의 경우에는 과거 주문 내역이나 평가가 없어 추천이 어려워지게 됩니다.
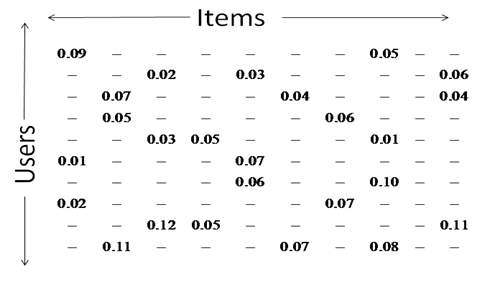
matrix를 채우는 Rating에는 두가지의 종류가 있는데, explicit feedback(명시 점수)와 implicit feedback(암묵 점수) 입니다. Explicit feedback는 음식점 별점과 같이 고객이 product에 대한 명확한 평가를 내린 점수를 말합니다. 반면 implicit feedback은 고객이 간접적으로 표현한 평가, 즉 상품을 눌러보고, 장바구니나 즐겨찾기에 추가하는 등의 행동 점수를 말합니다. 이번에 띵동에서는 explicit feedback을 사용하였기 때문에 sparse의 비율이 높은 편이었습니다.
Long tail problem (롱테일)
띵동의 이야기로 돌아와서, 띵동 앱내에는 다양한 음식점들이 있지만, 고객들은 소수의 인기 있는 음식점에 관심을 보입니다. 상대적으로 관심이 적은 다수의 음식점의 경우, 추천을 위한 충분한 주문/평가가 이루어 지지 못하는 경우가 많습니다. 이를 long tail problem으로 정의하며, long tail에 해당하는 음식점의 경우에 sparsity의 문제를 갖게 됩니다. 다양한 음식점을 추천하고 음식점 선택의 폭을 더욱 넓히기 위해, long tail 음식점에 대한 고려를 해야 했습니다. 하지만 단순히 모든 음식점들을 고려하는 것에 의미를 두는 것이 아닌, 고객이 선호하는 음식이 long tail에 존재할 가능성을 가지고 간다는 의미를 가집니다.



Hybrid의 방법은 크게 두가지로 나눌수 있습니다. 예를 들어, method 1과 method 2를 hybrid하게 된다면,
1. 두개의 methods를 각각 독립적으로 train하여, 각각 산출된 sugeestions을 합하는 방법 (independent)
2. 두개의 methods를 조합하여 한개의 method로 만든 다음, single model로 train하는 방법 (neural network)
여러가지 추천 모델을 가지고 가는 만큼, 모델 평가 결과에 따라 일부 모델은 제거할 계획을 가지고 있었기 때문에, 각 모델을 독립적으로 train/evaluate 가능한 첫번째 방법으로 진행하였습니다. 두번째 방법은 실질적인 feedback을 통한 모델 평가 이후, 선택된 모델들을 다시 single model로 조합하기로 하였습니다.
띵동의 음식점 추천 (Restaurant Recommender System)
- Funnel approach
시간적, 공간적 제약을 가진 음식점 추천의 특성과 sparsity, cold start를 보안하고자 YouTube의 “Funnel method” 를 변형시켜 적용하였습니다. 기존의 funnel method의 장점을 살리고 띵동 음식점 추천에 필요한 filter 단계를 추가하였는데요. 두 단계의 funnel를 사용함으로서, 단순히 accuracy(정확도)만 높히는 것이 아닌, precision(정밀도)을 최적화 시킬 수 있다는 장점이 있습니다. 대표적인 accuracy measurement인 MAE와 RMSE의 경우, 얼마나 정확한 rating을 예측하는가를 측정하는 척도입니다. 하지만 spare와 long tail의 특성을 고려해야하는 추천 시스템에서는 accuracy만 고려하게 되면 popular products만 추천하여 error를 낮추게 되는 경우가 생길 수 있습니다. 결국 낮은 measurement를 따라가게 된다면 long tail에 대한 예측 성능이 떨어지게 됩니다.


- Reinterpretation of ratings
explicit feedback인 음식점의 별점/리뷰를 사용하면서 생기는 sparity를 보안하기 위해, 반복 주문에 대한 가중치를 줌으로서 별점이 부여되지 않은 주문에 대한 예상 별점을 부여하였습니다. 예를 들어, 선호하는 음식일 경우, 혹은 음식에 대한 경험 (user experience)이 좋았을 경우에는 반복 주문을 했을 것이라는 가정을 바탕으로, 고객이 동일한 음식을 여러번 반복하여 주문하였을 경우, 별점이 없더라도 예상되는 별점을 할당하여 sparity의 비율을 줄였습니다. 이 때, 고객마다 별점을 주는 패턴(rating habits of users)도 함께 고려해야 합니다. - Exclusive pool
Cold start와 long tail을 보안하고자 추천 시스템에서 history가 없는 고객과 음식점을 별도로 분리하여 exclusive pool에 분리하여 처리하였습니다 (Fig.7). exclusive pool에 해당되는 고객은 신규 고객뿐 아니라, 비회원, 혹은 이전 주문 내역이 없거나 적은 고객도 포함되며, 음식점도 마찬가지로 신규 음식점 혹은 이전 주문 내역이 없거나 충분하지 않은 음식점이 포함됩니다. 처리 방식은 고객과 음식점을 다르게 하였는데요. 음식점의 경우, long tail에 해당되는 음식점이 되므로, 해당 음식점들만 모아서 음식점 유사도를 바탕으로 기본 추천 시스템과 별개로 추천하였습니다. 고객의 선호를 조사하는 단계가 없기 때문에, exclusive pool에 해당되는 고객의 경우, popularity를 기반으로 한 추천이 이루어 집니다. 향후에 고객들이 추가로 음식주문을 하게 되면 explicit feedback (별점/후기)가 반영되면서 추천 시스템으로 이동하게 됩니다.
결국 추천 시스템은 사용자(고객)이 원하는 것, 좋아할 거라고 예상되는 것을 시스템이 알아서 예측/제공해주는데 목적을 가지고 있습니다. 추천 시스템의 성능이 향상 될수록, 사용자가 검색 기능을 사용하는 빈도가 줄어들고 의사결정을 내리는 속도를 줄여 줄 것입니다. 먹고 싶은 음식을 검색하는 모습에서, 원하는 음식을 먼저 보여주는 모습으로 변화하기 위해, 현재 구축된 추천 시스템을 여러가지 관점/방법으로 평가하고 지속적으로 최적화 시켜 나갈 계획입니다.
4차 산업 혁명, 데이터를 마주하는 띵동 개발팀의 자세
4차 산업 혁명(데이터 혁명)의 정의에 대한 다양한 의견들이 있지만, 정보화 혁명의 심화, 혹은 그이상의 의미가 있다고 정의를 합니다. 정보화 시대가 도래한 이후 엄청난 데이터들이 쏟아져 나왔지만, 데이터 처리에 대한 능력과 기술부족으로 사실상 아무런 가치를 가지지 못했습니다. 4차 산업 혁명의 핵심인 ‘사물인터넷(IoT)’ 와 ‘인공지능(AI)’ 모두 데이터를 기반으로 첨단기술과 밀접한 관계에 놓여 지면서, 3차 산업 혁명(정보화 혁명)의 결과물인 데이터가 비로서 유의미한 자원이 됩니다.
4차 산업혁명의 시대가 도래하면서 우리의 삶은 과거의 그 어느 때보다 빅데이터, 블록체인, 인공지능 등의 첨단 기술과 밀접한 관계에 놓이게 되었다. 우리의 사회는 개인의 일상부터 국가 단위의 시스템까지 점차 데이터화 되고 있으며, 사회 경제적 패러다임 또한 데이터의 진화를 기반으로 바뀌고 있다. — 불온한 데이터 전시회, 현대 미술관
과거의 산업 혁명을 정의할 때는 이미 지나간 과거의 시대를 3차 산업 혁명이었다고 정의를 내렸고, 지금과 같이 우리가 4차 산업 혁명 시대에 살고 있다라고 현재를 정의하지는 않았습니다. 다만, 분명한 것은 지금 우리는 엄청난 정보와 데이터 속에 살고 있고 이를 다양한 분야에서 현명하게 접목시키는것이 현대사회를 살고 있는 우리에게 주어진 과제인 것 같습니다. 단순히 Machine Learning나 Deep learning을 사용한다는 것에 의의를 두는 것이 아닌, 보편화된 solution을 띵동에 맞게 최적화하고 발전시키는 것이 데이터를 유의미하게 만들고 현명하게 활용하고자 하는, 데이터를 대하는 띵동 개발팀이 추구하고 있는 자세입니다.
'기술블로그' 카테고리의 다른 글
| [띵동] Typescript 기반 범용 Domain NPM모듈 개발기 (0) | 2020.06.24 |
|---|---|
| [띵동] 띵동 데이터 대시보드 만들기 with Google Data Studio (1) | 2020.06.24 |
| [띵동] 2020 AWS Certified Developer — Associate 를 취득하기까지 (0) | 2020.06.24 |
| [띵동] AWS ECS(Elastic Container Service) 운영, 그리고 우리 이야기 (0) | 2020.06.24 |
| [띵동] 딜리버리 서비스와 개발팀 이야기 (0) | 2020.06.24 |



